En el campo de los Modelos de Lenguaje de Gran Escala (LLMs), existen una serie de términos técnicos que son fundamentales para comprender cómo funcionan estos poderosos modelos de inteligencia artificial. En esta lista, te presentamos los 50 términos más importantes, junto con explicaciones sencillas para facilitar tu comprensión del espacio LLM.
1. Modelo de Lenguaje de Gran Escala (LLM)
Un tipo de modelo de inteligencia artificial diseñado para comprender, generar y manipular el lenguaje humano prediciendo la siguiente palabra en una secuencia.
2. Arquitectura Transformer
Una arquitectura de red neuronal que utiliza mecanismos de auto-atención para procesar secuencias de datos, fundamental para muchos LLMs.
3. Mecanismo de Auto-Atención
Una técnica dentro de los transformers donde cada palabra en una oración se pondera según su relevancia para otras palabras, permitiendo que el modelo capture el contexto de manera más efectiva.
4. Tokenización
El proceso de convertir texto en tokens (palabras, sub-palabras o caracteres) que el modelo puede procesar.
5. GPT (Generative Pre-trained Transformer)
Una serie de LLMs desarrollados por OpenAI, preentrenados en un gran corpus de texto y afinados para tareas específicas.
6. Pre-entrenamiento
La fase inicial en la que un modelo se entrena en un vasto conjunto de datos para aprender patrones generales del lenguaje.
7. Afinado (Fine-tuning)
El proceso de continuar el entrenamiento de un modelo preentrenado en un conjunto de datos más pequeño y específico para adaptarlo a tareas concretas.
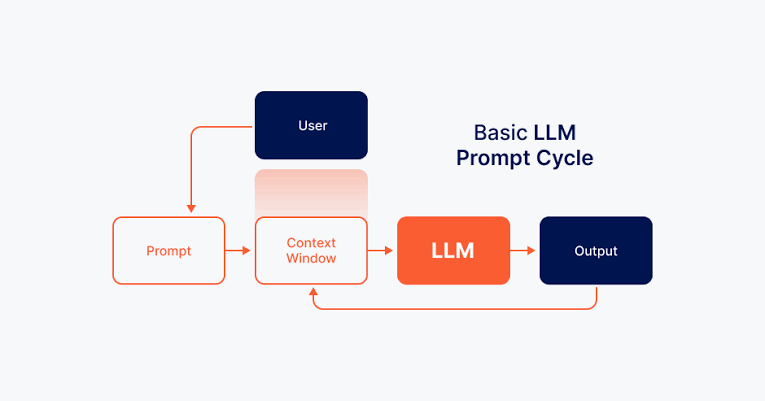
8. Ventana de Contexto
La cantidad de texto que el modelo puede considerar a la vez, generalmente definida por el número de tokens.
9. BERT (Bidirectional Encoder Representations from Transformers)
Un tipo de LLM diseñado para comprender el contexto de una palabra en una oración observando las palabras antes y después de ella.
10. Modelo de Lenguaje Máscarado (MLM)
Un enfoque de entrenamiento utilizado en modelos como BERT donde ciertas palabras son enmascaradas y el modelo se entrena para predecirlas.
11. Aprendizaje de Cero Ejemplos (Zero-Shot Learning)
La capacidad de un modelo para realizar una tarea sin haber sido explícitamente entrenado en ejemplos de esa tarea.
12. Aprendizaje de Pocos Ejemplos (Few-Shot Learning)
La capacidad del modelo para realizar una tarea después de haber recibido solo unos pocos ejemplos.
13. Ingeniería de Prompts
El proceso de diseñar entradas (prompts) para guiar el comportamiento de un LLM y generar los resultados deseados.
14. Procesamiento de Lenguaje Natural (NLP)
El campo de la IA centrado en la interacción entre las computadoras y el lenguaje humano.
15. Modelo Secuencia a Secuencia (Seq2Seq)
Una arquitectura de modelo utilizada para tareas donde la entrada es una secuencia de tokens y la salida es otra secuencia, como la traducción.
16. Decodificador
La parte de un modelo transformer responsable de generar secuencias de salida a partir de entradas codificadas.
17. Codificador
El componente de un transformer que procesa la secuencia de entrada y la codifica en un formato adecuado para la decodificación.
18. Cabeza de Atención
Una de las subunidades dentro del mecanismo de auto-atención, que captura diferentes aspectos del contexto de entrada.
19. Atención Multi-Cabeza
Un proceso en el que varias cabezas de atención trabajan en paralelo para capturar varios tipos de relaciones en los datos.
20. Embebido de Posición
La técnica utilizada para añadir información sobre la posición de las palabras en una secuencia al modelo, ya que los transformers no entienden inherentemente el orden de las palabras.
21. Embebido
Una representación vectorial densa de palabras, oraciones u otros tipos de datos que captura el significado semántico.
22. Aprendizaje por Transferencia
El proceso de utilizar un modelo preentrenado en una nueva tarea relacionada, aprovechando el conocimiento que el modelo ya ha aprendido.
23. Retropropagación (Backpropagation)
El algoritmo utilizado para ajustar los pesos en una red neuronal durante el entrenamiento propagando el error hacia atrás a través de la red.
24. Descenso de Gradiente
Un algoritmo de optimización utilizado para minimizar el error en el modelo ajustando iterativamente los parámetros del modelo.
25. Sobreajuste (Overfitting)
Una situación en la que un modelo tiene un buen rendimiento sobre los datos de entrenamiento, pero un rendimiento deficiente sobre datos no vistos debido a su excesiva complejidad.
26. Subajuste (Underfitting)
Cuando un modelo es demasiado simple para capturar los patrones subyacentes en los datos, lo que da lugar a un mal rendimiento tanto en los datos de entrenamiento como en los de prueba.
27. Hiperparámetros
Los parámetros de un modelo que se establecen antes de comenzar el entrenamiento, como la tasa de aprendizaje, el tamaño del lote y el número de capas.
28. Época (Epoch)
Un pase completo a través de todo el conjunto de datos de entrenamiento.
29. Tamaño de Lote (Batch Size)
El número de ejemplos de entrenamiento utilizados en una iteración del entrenamiento.
30. Tasa de Aprendizaje (Learning Rate)
Un hiperparámetro que controla cuánto debe cambiar el modelo en respuesta al error estimado cada vez que se actualizan los pesos del modelo.
31. Regularización
Técnicas utilizadas para prevenir el sobreajuste penalizando modelos complejos, como la regularización L2.
32. Dropout
Una técnica de regularización donde las unidades aleatorias en la red son ignoradas durante el entrenamiento para evitar el sobreajuste.
33. Función de Activación
Una función aplicada a la salida de una capa de red neuronal, introduciendo no linealidad en el modelo (ej., ReLU, Sigmoide).
34. Softmax
Una función de activación utilizada a menudo en la capa de salida de un clasificador para convertir logits en probabilidades.
35. Logits
Las puntuaciones crudas y no normalizadas generadas por un modelo antes de aplicar una función softmax.
36. Modelo de Lenguaje
Un modelo estadístico que asigna probabilidades a secuencias de palabras o tokens, prediciendo la probabilidad de una secuencia dada.
37. Búsqueda por Haz (Beam Search)
Un algoritmo de búsqueda utilizado para generar secuencias manteniendo un seguimiento de múltiples secuencias en cada paso y solo manteniendo las mejores.
38. Perplejidad
Una medida de qué tan bien un modelo de lenguaje predice una muestra; menor perplejidad indica un mejor rendimiento.
39. Espacio Latente
El espacio abstracto y multidimensional donde el modelo representa diferentes características o conceptos aprendidos durante el entrenamiento.
40. Red Neuronal
Una serie de algoritmos que imitan el cerebro humano para reconocer patrones y tomar decisiones.
41. Parámetros
Los pesos y sesgos dentro de un modelo que son aprendidos a partir de los datos durante el entrenamiento.
42. Evaluación
El proceso de evaluar las capacidades y la calidad de un LLM, típicamente contra un conjunto de datos de referencia o por humanos.
43. Puntuación de Atención
El valor calculado durante el proceso de auto-atención que determina la importancia de una palabra respecto a otra en una secuencia.
44. Comprensión del Lenguaje
La capacidad de un modelo de IA para comprender y dar sentido al lenguaje humano, más allá de simplemente procesarlo.
45. Inferencia
El proceso en el que un modelo de IA toma una entrada y genera una salida.
46. Generación de Lenguaje Natural (NLG)
El proceso de generar texto similar al humano a partir de un modelo, utilizado en chatbots, traducción y resumen.
47. Aprendizaje por Refuerzo con Retroalimentación Humana (RLHF)
Una técnica en la que un modelo es afinado utilizando retroalimentación de humanos para mejorar su rendimiento en tareas.
48. Auto-codificador (Autoencoder)
Un tipo de red neuronal utilizada para aprender representaciones eficientes (codificaciones) de datos, típicamente para reducción de dimensionalidad o reducción de ruido.
49. Pérdida de Entropía Cruzada (Cross-Entropy Loss)
Una función de pérdida común utilizada en problemas de clasificación que mide la diferencia entre las distribuciones predicha y real.
50. Destilación de Conocimiento (Knowledge Distillation)
Una técnica en la que un modelo más pequeño (estudiante) es entrenado para imitar el comportamiento de un modelo más grande (maestro) para reducir la complejidad mientras mantiene el rendimiento.
Este listado proporciona una visión general de los conceptos más relevantes en el espacio LLM y puede ayudarte a entender mejor cómo funcionan estos modelos avanzados de inteligencia artificial.